Final publication date 29 Aug 2024
Analysis of Carbon Emission Reduction Effects by Future Mobility Adaptation Scenarios Using a Large Language Model

Abstract
Mobility refers to mobile possibility and various mobility activities, including various means and services. The development of mobility affects the improvement of accessibility within the city and impacts not only the spatial structure but also the environmental pollution and social equity of the city. Self-driving cars and urban air mobility have recently emerged, and various influences on the environment and society have become issues. The emergence of GPT, a conversational artificial intelligence chatbot developed by OpenAI, a leading AI research foundation in the United States, in November 2022 has sparked a surge of activities integrating artificial intelligence across various fields. This study therefore aims to build an optimal future mobility scenario (model) by deriving and designing various mobility introduction scenarios using prompt engineering based on Generative AI. Using Generative AI, it is possible to create various scenarios at a low cost, in a short amount of time, and to envision scenarios and analyze effects based on various conditions through user-based prompts. To this end, this study creates a database drawing on previous literature, factors affecting mobility change and use, evaluation indicators, policies, and businesses to use for scenario development and evaluation. The findings will subsequently be applied to various Large Language Models based prompt tools such as GPT 4.0 and Llama-2 to configure various scenarios and to compare them to each other to identify the most optimized scenario. Finally, we will propose a framework that develops a set of scenarios based on the user’s prompts and predicts future effects in order to analyze the carbon emission reduction effects. The research results will be used as basic data for future city policies and plans aimed at carbon neutrality and will contribute to sustainable urban development.
Keywords:
Mobility Scenarios, Scenario Analysis, Generative AI, Prompt Engineering키워드:
모빌리티 시나리오, 시나리오 분석, 생성형 인공지능, 프롬프트 엔지니어링Ⅰ. Introduction
1. Research Background
Mobility is a concept that encompasses a wide range of mobile activities, along with the means and services to implement them. Technological advancements in mobility therefore not only help shape the spatial structure of cities but also significantly affect urban environments and social equity among urban dwellers. The recent emergence of various mobile means, such as mobility as a service (MaaS), autonomous vehicles (AVs), personal mobility, and urban air mobility (UAM), is expected to bring significant changes to a broad range of urban activities (Yigitcanlar et al., 2019; Zuev et al., 2019). While the increased availability of advanced mobile means does contribute to ensuring accessibility and mobility equity for different social layers (Piccinini et al., 2016), some argue that such advancements may also deteriorate traffic flow and increase carbon emissions (Diao et al., 2021). Despite their advantages, these newly emerged mobile means carry risks of excessive energy consumption, increased carbon emissions, and worsening urban pollution, causing serious environmental and societal concerns. Against this backdrop, it is important to predict and respond to potential changes in mobility in the future. To this end, developing suitable mobility scenarios in advance will be critical. The development of optimal execution scenarios, where carbon emissions and traffic disruptions caused by new mobile means are minimized and such mobile means are effectively operated to meet the needs of urban environments, especially their spatial structure, would lead to the successful implementation of carbon-neutral cities. However, most previous studies derived future mobility scenarios based solely on literature reviews rather passively, failing to fully explore a large pool of possible cases. In an effort to address this limitation, this study leveraged generative AI models to automatically generate multiple scenarios by considering various conditions and variables.
2. Purpose of Research
The aim of this study is to develop technology capable of automatically generating various future mobility scenarios and analyze the reduction in carbon emissions by each scenario. To this end, generative AI models were trained with the data and resources obtained from extensive research on mobility. Prompt engineering was then employed to derive scenarios using the AI models, and the obtained results were compared. To be specific, the objectives of this study are as follows. First, this study focuses on creating a database on mobility to employ as a basis for deriving future mobility scenarios. This procedure involves reviewing the findings of previous studies that have primarily served as the foundation for developing existing mobility scenarios, and systematically putting the analysis results in order. Notably, prompt engineering is employed to reconstruct the analysis results in the form of question-answer (QA) pairs, enhancing the effectiveness of model training. Second, this study attempts to train generative AI models for use in developing large language model (LLM)-based mobility scenarios. This process is executed based on the database created in the previous stage. The trained models can be used to generate various mobility scenarios in response to users’ questions and assess their effectiveness. Third, prompts for evaluation of the mobility scenarios are generated, and the quality of each scenario is assessed accordingly. Given that the outputs of AI models are influenced by the prompts entered by users, prompts are carefully designed to allow each model to analyze the reduction in carbon emissions through future mobility scenarios. The AI models’ outputs in response to the developed prompts are compared for optimization. Finally, the potential reduction in carbon emissions is analyzed based on the derived mobility scenarios, and based on the results, implications for future urban planning are proposed.
Ⅱ. Theory and Literature Review
1. AI Technology and Generative AI
Initiated from the concept of the artificial neural network, artificial intelligence (AI) has been evolving into a versatile tool that handles a wide variety of tasks, from computation and pattern analysis to image analysis, thanks to the ongoing development of different types of neural networks (McCulloch and Pitts, 1943; Rosenblatt, 1958; LeCun et al., 1998; Cao et al., 2023). AI is now being used in various fields, further extending its scope of application to urban planning—analyzing urban data, assisting with the planning process, and providing novel insights into urban design (As et al., 2022). Specifically, AI serves as an effective tool, enabling urban planners to manage traffic conditions, pollution, and energy consumption by collecting massive time-series data, detecting patterns from the data using algorithms, and overseeing the identified patterns. For example, in Singapore, AI-based systems are employed to predict the country’s future urban population and the corresponding demand for social and community services, optimizing the location of urban infrastructure and the accessibility of such services.
Notably, AI is highly effective in natural language processing and analysis. AI models capable of asking and responding to questions, such as ELIZA, were developed as early as the 1960s when AI technology was in its infancy (Buchanan, 2005). Since then, the application of AI in natural language processing has been exponentially growing. The emergence of Transformers, which provide enhanced processing speeds by considering contextual interactions, has spurred the development of various large language models (LLMs), such as Bidirectional Encoder Representations from Transformers (BERT) and Generative Pre-Trained transformer (GPT) (Cao et al., 2023). This technological breakthrough has recently opened the door to the use of generative AI. This AI technology is capable of generating various forms of data, including text, images, and voices, in response to user prompts. It outperforms existing chatbot systems, extending its scope of application to more sophisticated tasks, including music creation, stock forecasting, and medical assistance (Brühl, 2023).
Notably, AI chatbots specially designed for natural language processing have proved to be effective communication tools to facilitate information exchange between urban planners and citizens. This communication effectively increases urban dwellers’ understanding of decision-making in urban planning, helping them understand various perspectives. Recently, the use of generative AI has gone beyond just assisting with urban planners’ design process by also automating the urban design process. For example, generative AI-based systems can be trained with previous cases of urban design in block units and propose new urban plans by considering various parameters, including the characteristics of land within specific blocks.
2. Prompt Engineering
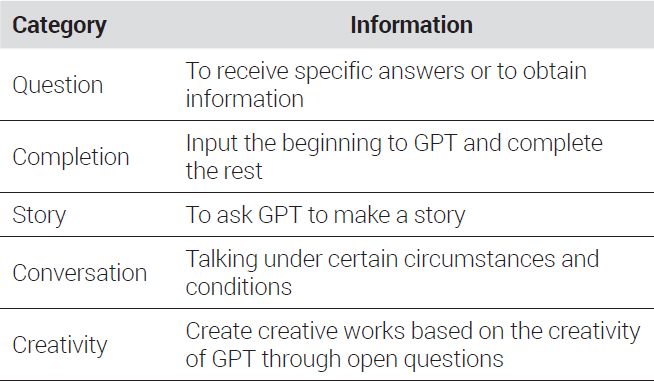
Prompt engineering is the practice of designing inputs for AI tools that will produce optimal outputs. This process is critical in encouraging generative AI systems to function as desired by users for a wide variety of applications (Learn Prompting, 2023; Shin et al., 2020). Optimizing prompts significantly reduces the time and effort required by reducing redundant or unnecessary questions and minimizing irrelevant or wrong responses. Prompt engineering is particularly effective in guiding natural language processing-based and LLM-based AI tools to offer high-quality outputs (Zhu et al., 2023). Prompt categories typically used in prompt engineering are presented in <Table 1>.

Five categories of prompts
In addition to these prompt settings, the temperature parameter can also be used to improve the quality of outputs produced by LLM-based tools. It is a parameter used to control the randomness of the LLM’s responses driven by AI predictions (Holtzman et al., 2020). The temperature parameter ranges between 0 and 1; as its value is closer to 1, the model’s responses become more diverse and flexible. As the value is closer to 0, the model’s responses are more deterministic and less creative, exhibiting limited diversity (Radford et al., 2019).
3. Mobility
In most previous studies, mobility scenarios were developed and analyzed based on literature reviews. The researchers conducted systematic literature reviews to identify patterns commonly observed across different studies and break them into detailed categories to derive mobility scenarios. Miskolczi et al. (2021) categorized 62 relevant studies according to various keywords, including vehicles, shared mobility, and electric mobility devices. The researchers ultimately derived four mobility scenarios and analyzed their annual trends. However, socioeconomic factors, such as demographic characteristics and usage rates of transportation systems, must also be taken into account when developing specific mobility scenarios. To be more specific, predicting future mobility requires considering mobility indexes, such as the mode share for public transportation (Agriesti et al., 2020). Furthermore, the emergence of new technologies—electric vehicles, shared mobility services, and extended transportation systems—significantly affects the configuration of future mobility scenarios (Butler et al., 2020). In response to the introduction of new types of transportation systems, urban mobility must be analyzed in a systematic manner (Grindsted et al., 2022). The focus of this discussion is on whether these systems will contribute to extending and accelerating the growth of the existing car-oriented transportation system, or whether such systems will find new paths toward sustainable mobility (Leal et al., 2022).
4. Distinctive Features of This Research
Conventional approaches in this field of research have relied on comparing existing scenarios and opinions from a limited number of experts to develop a macroscopic framework for deriving new mobility scenarios (Miskolczi et al., 2021). However, these approaches require extensive time and costs and entail a risk of jumping to conclusions based on a limited set of alternatives. Against this backdrop, this study proposes a novel approach to developing mobility scenarios using LLM tools. More specifically, an LLM training methodology to effectively explore various future mobility scenarios, described in the literature and reports on mobility, is introduced. This methodology allows for thorough inquiry based on different future mobility scenarios, promoting both urban planners’ and city dwellers’ understanding of the mobility scenarios while offering necessary information. Compared to existing methodologies, this innovative AI-based scenario creation method is more efficient and reactive to socioeconomic changes, providing more comprehensive predictions for future mobility. Overall, this study differs from others in that it proposes a novel methodology that enables anyone to explore both the direct and indirect effects of different factors on various scenarios for specific topics in a qualitative manner.
Ⅲ. Analytical Methodology
1. Analysis Methods
This study aims to train LLM models designed to generate mobility scenarios and use them to analyze the potential reduction in carbon emissions. In an effort to achieve these goals, data are collected, models are selected, and scenarios are generated. First, data collection is a process in which basic data for LLM model training are collected. In this study, two data sources were employed: open-access academic papers available on Scopus and reports made available by public institutions and consulting firms. Subsequently, preprocessing was performed, followed by data processing. Second, in model selection, the data processed in the previous step were reconstructed in the form of question-answer (QA) pairs for use in fine-tuning. Fine-tuning is the process of optimizing a pre-trained model using additional data to enhance its applicability and accuracy in a specific domain (Ziegler et al., 2019). In the course of fine-tuning, underlying models are selected, and the final one to use is then determined by comparing the results before and after the fine-tuning process. Finally, during scenario generation, the selected model is employed to create mobility scenarios using prompts, and the potential reduction in carbon emissions is predicted and analyzed based on the derived scenarios. The overall flow chart of the analysis method adopted in this study is illustrated in <Figure 1>.

Research framework
2. Data Collection
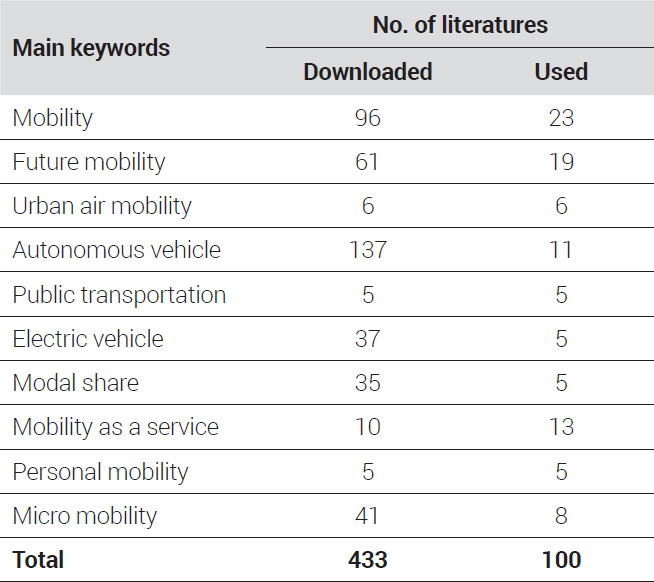
In this study, future mobility scenario data were collected from open-access academic papers available on Scopus and reports made available by public institutions. Specifically, relevant resources were searched for and gathered using search keywords chosen to align with the research purpose. The keywords for searching for relevant academic papers and reports may be selected to include terms directly related to changes in mobility and a means of transportation, such as future transport, future mobility, mobility scenarios, and autonomous vehicles (Miskolczi et al., 2021). In this study, 10 main keywords containing terms related to mobility scenarios were selected. Additionally, scenarios, trends, and demand were selected as sub-keywords. Different combinations of the main keywords and sub-keywords were used for the search process. The main keywords and sub-keywords used in this study are summarized in <Table 2>.
Keywords for searching papers
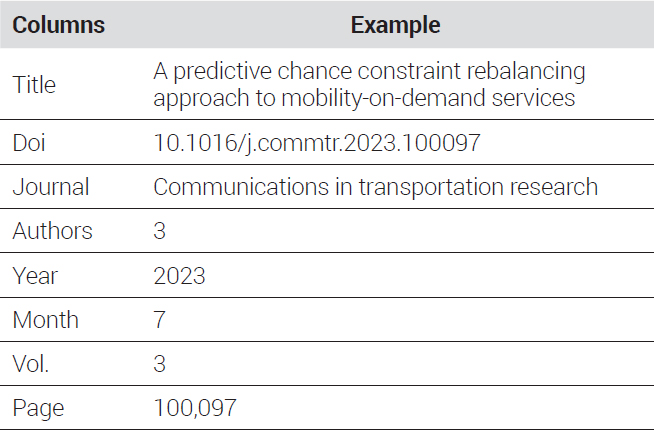
Additionally, the search range was limited to the recent papers issued within the period from 2019 to 2023, which were less likely to have been used to train publicly available LLM tools. Paper search and data storage were performed using Python, a programming language, and the application programming interface (API) of Scopus, an online academic journal database. Metadata for each paper were cumulatively stored in spreadsheet format. The components and examples of these metadata are presented in <Table 3>.
Meta data for collected papers
Subsequently, the full text of each paper was stored in text format using Science Direct’s API. Science Direct’s API offers free access to the publications available in Elsevier’s database while also enabling users to find papers using their titles and DOIs and download them in the format they desire (Yang et al., 2017). For papers whose full text could not be accessed on Science Direct, the full texts were manually obtained from the corresponding journals’ websites. For government and corporate reports, only those publicly available that could be found by keyword search were gathered in PDF format and later converted into text format for storage. The primary focus of the literature collection process was to gather and store as many papers and documents as possible through searches using the keywords selected. This approach was taken because the size and quantity of data available in the fine-tuning process may affect the performance of LLM tools (Penedo et al., 2023).
The collected literature was processed into a format suitable for fine-tuning using Shorten GPT. Shorten GPT is a GPT 3.5-based model created by OpenAI specifically designed to summarize text or PDF files to the desired length. For example, a text of one million words can be shortened to approximately half a million words for a more concise summary using Shorten GPT, with its shortening ratio being set to 0.5. That said, this process is not a mere reduction of the word count but a skillful summarization considering the overall context and key points of the document based on GPT, a pre-trained LLM. Therefore, the shortening ratio mentioned above does not represent the reduction in the document’s length but the degree of summarization from an abstract perspective. In this study, Shorten GPT was employed to prioritize the inclusion of the important or relevant parts of the collected papers and reporters while excluding less relevant information. Notably, it was ensured that mobility-related trends, statistics, figures, and contexts related to their changes must be included in summaries. Those with limited relevance were deemed to have been recognized by GPT as less important considering the overall context. Thus, these parts were deleted to reduce the cost and time required for model training. Finally, prompts were created as guidelines for GPT’s summarization, as shown below.
Leave out information about authors (organization), participants, thanks to, sources, and references. Shorten the paper into 17000 characters by selecting important parts of the paper. The result doesn’t have to be in a full sentence. Only include important parts. The important parts are mobility trends, mobility scenarios, factors that affect mobility trends, predictions and estimations, and detailed statistics and numbers.
The text summarized by Shorten GPT must be converted into QA format for fine-tuning. This type of data falls into the Question category among the prompt categories required in prompt engineering. An AI model trained with this type of data can be later used as a prompt-based model for the desired domain. In this study, the summarized text was preprocessed using GPT 4.0. This procedure aimed to convert the summarized text into QA format, especially centered on content related to mobility scenarios. The purpose of the Question was defined as “providing information about future mobility scenarios and their trends” as a working guideline for ensuring concreteness. For example, a summarized text can be converted as follows: {“Q: What is the predicted demand for electric vehicles in 2030?” “A: According to a 2020 report by McKinsey, their demand is expected to increase by n% compared to the 2020 level.”} This text is then stored in JSON format for use in model training. 20 QA pairs for each of the summarized papers or reports were prepared to compare the performance of models before and after fine-tuning. The prompts generated for data preprocessing in this study are as follows.
You are a mobility professor trying to teach students about the future scenario and trend of mobility. The purpose of the question is to teach about the future scenario and trend of mobility.
Generate 20 questions and answers according to what you think are important in the text above.
Focus more on the scenario, prediction, and trend of future mobility. Also be sure to include specific numbers and statistics.
The result should be in the format of {“instruction”: “question”, “output”: “answer”}.
Turn the result into a table with columns that consist of instruction, context, response, category.
Categories should be classified into closed_qa, classification, open_qa, information_extraction, brainstorming, general_qa, summarization.
Put " marks at the start and the end of strings.
Change the table into json format.
3. Analytical Models
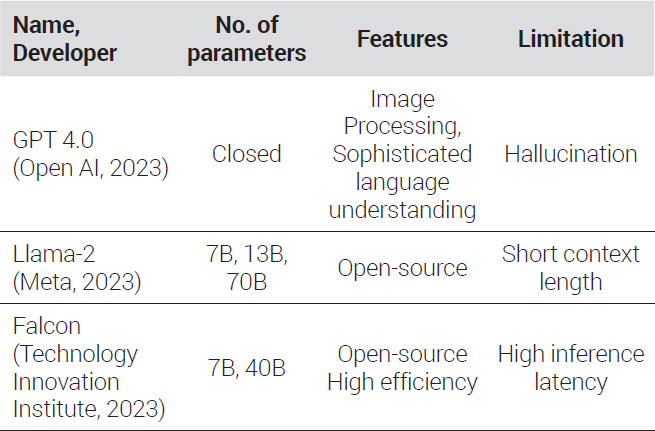
LLM training requires both data containing an extensive number of parameters and massive computing resources. Consequently, LLM development and training at the individual level are limited. Nonetheless, big tech companies, such as OpenAI, Meta, and Google, have developed open-source LLMs and made them available for anyone to use for educational and commercial purposes. In this study, three publicly available LLMs, including GPT 4.0, Llama-2, and Falcon, were selected for analysis. All three models are known for their superiority in language understanding and processing and for being easy to use. As an LLM based on ChatGPT, a web-based service, GPT 4.0 is well-suited for prompt engineering. Llama-2 and Falcon are easy to use for anyone, as their development and fine-tuning processes are openly available. Therefore, these models can be optimized to perform tasks in specific domains through fine-tuning without additional costs. The models employed in this study are summarized in <Table 4>.
Features of different LLM models
While it was possible to derive scenarios using publicly available models only, in this study, the performance of models was compared before and after fine-tuning for future mobility optimization. Fine-tuning was performed for Llama-2 and Falcon only because GPT 4.0 did not allow for fine-tuning. A 7B model was used as the pre-trained model. The QA-format data obtained through preprocessing were employed for fine-tuning using A100, a paid graphic processing unit (GPU) service provided by Google Colab, which offers cloud computing services.
IV. Analysis Results
1. Mobility Scenario Database
In this study, papers and reports related to mobility scenarios were gathered for use in developing a database for LLM fine-tuning. Initially, all papers and reports identified through a keyword search were gathered, and duplicate documents were removed. As a result, a total of 433 documents were collected. Subsequently, Chat GPT 4.0 was employed to select the list of documents for the final analysis. More specifically, the prompts presented below were used to find documents that were highly relevant to the research theme, especially based on their metadata. As a result, a total of 100 documents were selected. The number of documents finally selected is presented with respect to each keyword in <Table 5>. Each document was then subjected to summarization using Shorten GPT. In this process, important content, statistics, and figures related to mobility scenarios were preserved, while unnecessary information regarding authors and businesses was excluded. The shortening ratio was set to 0.5 to maximize training efficiency.
Number of papers including each main keyword
“I will provide a list of literature metadata. The literature contains academic papers and public reports.
As a mobility expert you have to choose 100 of them to reference to make a future mobility scenario and predict carbon emissions.
You must consider the change of future mobility and mobility scenarios, mobility trends, and so on. Give me a list of 100 literature you will choose.”
2. Comparison between Models
The results of prompt engineering were analyzed to compare the overall performance of each model. To be more specific, prompts were created to allow each model to envision three mobility scenarios from optimistic, neutral, and pessimistic perspectives, respectively, and to provide detailed descriptions of each scenario. The models were also asked to quantify the reduction in carbon emissions in each scenario compared to the 2019 level. For the temperature parameter, the default value of each model was adopted.
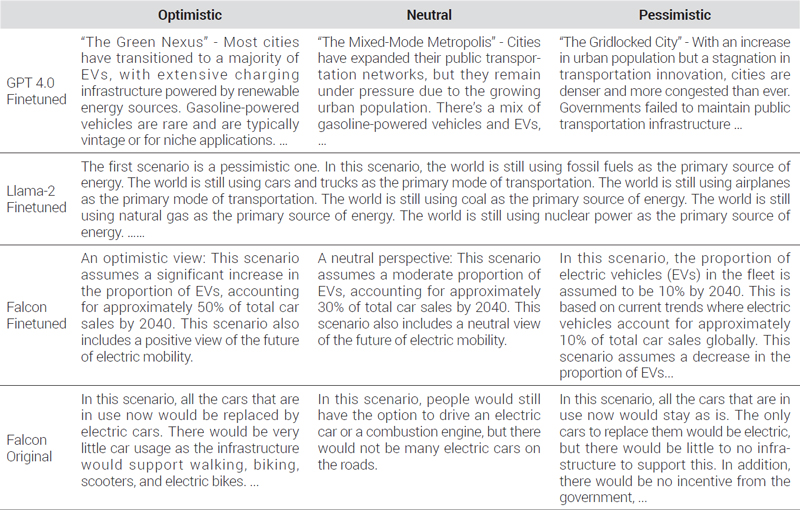
GPT 4.0 derived relatively high-quality hypothetical scenarios in everyday terms, providing detailed descriptions of the themes from the three perspectives. However, the model did not allow for fine-tuning. Moreover, when the amount of data for learning was more than three pages long on A4-sized paper in QA learning settings, GPT 4.0 began forgetting pre-trained knowledge. Llama-2 did not follow the given guidelines and repeated the same phrases. These errors were deemed to have been caused by incomplete fine-tuning. Meanwhile, in its optimistic scenario, Falcon detailed the reasons for the potential reduction in car usage and also explained the rationale behind its predictions, along with the reason why people used cars. Furthermore, the model derived the most realistic neutral and pessimistic scenarios compared to the other two models, with detailed figures regarding carbon emission reduction. Overall, Falcon was recognized as the most suitable model to provide the highest-quality mobility scenarios. Therefore, further fine-tuning was performed on Falcon. The prompts used for this model comparison are shown below, and the outputs of each model are summarized in <Table 6>.
Each individual model’s response to the promp
“As an expert in mobility, I would like you to envision three distinct scenarios for urban mobility in the years 2040.
Your task is to provide detailed descriptions for each scenario, considering a pessimistic, neutral, and optimistic perspective.
Additionally, I would like you to compare the carbon emissions associated with these scenarios to the carbon emissions observed in 2019 in percentage.
Please ensure your response is comprehensive, precise, and of high-quality”
3. Outputs of the Generative Models
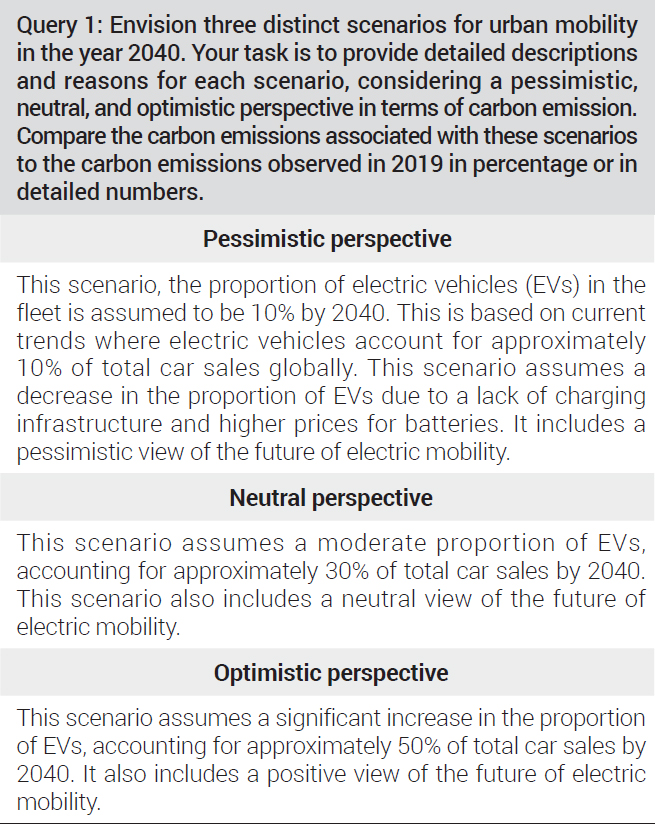
The fine-tuned model for everyday conversations and the final fine-tuned model were prepared, and their responses to Question 1 are presented below. The fine-tuned model for everyday conversations simply repeated specific content in the query and failed to derive exact figures. On the other hand, the final fine-tuned model provided outputs based on the proportion of EVs in the fleet. Its three scenarios from the predefined perspectives exhibited different proportions of EVs; the figure increased linearly from the pessimistic to neutral and optimistic perspectives. These results confirmed the effectiveness of fine-tuning in enhancing the learning performance of the model by training it with additional new data. The fine-tuned model was asked to derive various mobility scenarios in response to different queries. The three scenarios derived from the fine-tuned Falcon model are presented in <Table 7>.
Model’s response about three different scenarios
The second question regarded future urban mobility beyond EVs and public transportation. The model mentioned the potential usage and limitations of EVs in the future, along with descriptions of eVTOL and bicycles as alternatives. The prompts used, along with the model’s outputs, are summarized in <Table 8>.
Model’s response about future urban mobility
Subsequently, the model was asked what transportation systems, beyond existing mobility options, would contribute to effectively reducing carbon emissions. The model mentioned autonomous vehicles, EVs, hydrogen fuel cells, and biofuels. The prompts used, along with the model’s responses, are presented in <Table 9>.
Model’s response about the potential of new mobility reducing carbon emissions
The next question concerned the possibility of a large-scale adoption of EVs, among the most promising future mobility options, and the challenges that EVs currently faced. The model responded that the current challenges in the adoption of electric mobility included high upfront costs, inadequate charging infrastructure, and lack of consumer awareness. The prompts used, along with the model’s outputs, are shown in <Table 10>.
Model’s response to EV adoption rate
Finally, the model was inquired about the role of urban planning in shaping future mobility trends and reducing carbon emissions. The model answered that urban planning could be a key to reducing traffic congestion and maximizing the utility of public transportation by enhancing efficiency in traffic management. As specific measures, it highlighted the significance of urban planning and policy-making that prioritized walking and cycling over cars, stating that all these efforts would help reduce carbon emissions in urban areas. The prompts used, as well as the model’s outputs, are summarized in <Table 11>.
Model’s response of the effect of urban planning
4. Analysis of Carbon Emission Reduction
The potential reduction in carbon emissions by future mobility options was analyzed by the fine-tuned Falcon model. The future carbon emission scenarios proposed in the sixth report of the Intergovernmental Panel on Climate Change (IPCC) were used as a reference to assess the accuracy and errors of the model. The IPCC is an intergovernmental panel dedicated to climate change issues, established by the World Meteorological Organization (WMO) in 1988. The institution has provided regular scientific assessments on the risk of climate change due to human activities and the corresponding feasible measures, for example, by issuing reports on climate change (Chaewoon Oh et al., 2023). Given the nature of its activities, the IPCC’s sixth report was deemed to be suitable for comparison with the outputs of the analytical model employed in this study. The optimistic, neutral, and pessimistic mobility scenarios derived in this study were compared with their comparable counterparts proposed in the IPCC’s sixth report, i.e., SSP1, SSP2, and SSP3, respectively. For a consistency analysis, prompt engineering was employed to train this study’s analytical model with the carbon footprint-related data dated up to 2019 in the IPCC’s sixth report. In all of its three scenarios, the model analyzed that global carbon emissions had reached approximately 36.44 Gt by 2020, indicating that the promptbased training approach had been successful.
The analysis results are as follows. According to its pessimistic scenario on carbon emissions, various factors would hinder urban growth, including the persistent reliance on fossil fuels, delayed adoption of EVs, inadequate public transportation, urban expansion, and technological slowdown. The model’s mentioning of the delayed adoption of EVs confirmed that fine-tuning and prompt engineering had been successful in enhancing the quality of traffic scenario predictions. Furthermore, the model analyzed that, given sluggish economic growth, carbon emissions would increase annually by approximately 2%, thereby driving global carbon emissions to approximately 177.66 Gt by 2100. This pessimistic scenario was largely consistent with the SSP3 scenario of the IPCC report.
Meanwhile, its neutral future scenario on carbon emissions analyzed a modest increase in the adoption of renewable energy sources, growing adoption of EVs, gradual advancements in the public transportation system, and a gradual transition to sustainable urban planning and carbon capture and storage (CCS) technology. The model’s reference to the adoption of EVs and gradual advancements in the public transportation system indicated the successful execution of fine-tuning and prompt engineering for mobility scenario predictions. By assuming modest economic growth, this scenario analyzed that carbon emissions would decrease annually by 1%, and this trend coincides with that found in the SSP2 scenario of the IPCC report.
Finally, its optimistic scenario identified factors that might facilitate urban growth-exponential advancements across various sectors, including renewable energy technology, EVs, public transportation, sustainable urban planning, and CCS technology. The successful implementation of fine-tuning and prompt engineering was confirmed by the model’s acknowledgment of renewable energy sources, EVs, and public transportation. Given rapid economic growth, the scenario analyzed an annual emission reduction of approximately 7% and offered specific figures, suggesting that global carbon emissions would have reached approximately 0.11 Gt by 2100. This scenario was comparable to the IPCC report’s SSP 1 scenario. The prompts used to analyze the potential reduction in carbon emissions and the corresponding results are summarized in <Table 12>.
Model’s response about three carbon emission scenarios
V. Conclusions
1. Discussion and Conclusions
This study aimed to generate various future mobility scenarios and use them to analyze the potential reduction in carbon emissions, especially with specific figures. To this end, generative AI models were fine-tuned based on an extensive body of literature. More specifically, the outputs of various large language models (LLMs) were compared to select the optimum model capable of generating the highest-quality scenarios. The selected model was then allowed to generate future mobility scenarios from optimistic, neutral, and pessimistic perspectives, respectively. In its mobility scenarios, the model analyzed that the potential reduction in carbon emissions would have reached different levels, ranging from 75% to 25% by 2040 depending on the perspectives considered. From a technological perspective, the model concluded that the maximum reduction in carbon emissions would necessitate accelerated commercialization of autonomous vehicles and a growing adoption of EVs, and that private vehicles on the road should be reduced through the growth of shared mobility services. From a policy perspective, the model highlighted the improvement of charging infrastructure for EVs, policy-making prioritizing public transportation, and urban planning that encouraged people to walk and use public transportation. Applying this methodology to train more sophisticated models with even more extensive data could make it possible to precisely estimate the diverse effects of potential changes in national land and urban policy in the future on mobility and the corresponding change in carbon emissions.
The major findings of this study hold significance from three key perspectives: social aspects, policy-making, and academic and educational points of view. From a social perspective, this study contributes to predicting future mobility scenarios considering socioeconomic changes, assisting urban dwellers in preparing for and responding to the realization of a carbon-neutral society. Additionally, this study helps validate the legitimacy of the usage of and investment in emerging urban mobility options, including public transportation and autonomous vehicles. From urban policy perspectives, the results of this study can be used as basic research data to help establish strategies for responding to potential changes in future urban mobility while also providing effective comparative analysis and evaluation tools, supporting policy-making and bill-drafting processes for urban planning. Finally, from academic and educational perspectives, this study proposes a novel methodology for applying fine-tuning to generative AI models designed for specific tasks, as well as dataset development. Furthermore, it will also contribute to enhancing the efficiency of AI training through prompt engineering. Overall, the application of the developed methodological framework to national land and urban planning will contribute to addressing the limitations of previous studies, either through convergence with existing solutions or by fostering the development of even more innovative approaches.
2. Limitations of the Study
This study entails the following limitations. First, the accuracy of the data used for scenario generation, as well as the validity of their sources, could not be verified. There was no guarantee that the predictions proposed in the papers and government reports employed in fine-tuning would be accurate. Furthermore, the accuracy of the data previously used in the training of the Falcon LLM could not be verified either. This is the most well-known limitation of GPT as an LLM. Therefore, rather than predicting the potential reduction in carbon emissions by changes in mobility with 100% accuracy, this study focused on estimating the effect of mobility variations induced by changes in urban structure and policy on trends in carbon emission reduction, ensuring that future urban policy and the adoption of emerging mobility options could be implemented to the benefit of the public at large. In future studies, prediction accuracy is expected to improve by employing more sophisticated models and expanded datasets. Second, the Falcon model’s outputs generally fell into the category of common knowledge. This limitation was attributed to the inadequate performance of the developed model due to its limited computing power, combined with the fine-tuning process conducted based on a limited body of data. Despite these shortcomings—limited data and resources—the Falcon model, which initially had little knowledge about mobility, came to acquire a significant amount of knowledge regarding mobility issues through fine-tuning. Future studies will focus on performing fine-tuning using more refined models and increased data to achieve more accurate and sophisticated outputs. Finally, the validity of both the scenarios and predictions on carbon emission reduction derived by the LLM developed in this study was not sufficiently verified. This limitation can be attributed to the black-box nature of LLM tools; the process through which models answer questions is not fully understood. Additionally, given that the data used for fine-tuning were based primarily on future traffic demand, the predictions on carbon emissions made in this study could possibly be underestimated or overestimated. Furthermore, the predictions on carbon emissions made for the period from 2020 to 2100 were not presented in exact numbers but were provided in the form of scenarios. Therefore, future studies should focus on verifying the validity of the QA process used in this study by comparing the outputs with existing scenarios and employing expert assessments. Through this approach, it will be possible to assess the applicability of LLM models and further specify questions, thereby confirming the validity of the entire procedure.
In future studies, prompt engineering should be performed not only with qualitative data from the literature but also with quantitative results from actual measurements to enhance the quality of scenarios in terms of clarity, thus offering an advanced methodology to achieve sustainable urban environments.
Acknowledgments
This research was funded by the Ministry of Education and the National Research Foundation of Korea (NRF-2023S1A5B1076175). This paper was prepared by revising and updating part of a paper presented at the 2024 Spring Conference of the Korea Planning Association.
References
-
Agriesti, S., Brevi, F., Gandini, P., Marchionni, G., Parmar, R., Ponti, M., and Studer, L., 2020. “Impact of Driverless Vehicles on Urban Environment and Future Mobility”, Transportation Research Procedia, 49: 44-59.
[https://doi.org/10.1016/j.trpro.2020.09.005]
- As, I., Basu, P., and Talwar, P. (Eds.), 2022. Artificial Intelligence in Urban Planning and Design: Technologies, Implementation, and Impacts, Amsterdam: Elsevier.
-
Brühl, V., 2023. “Generative Artificial Intelligence (GAI)– Foundations, Use Cases and Economic Potential, Center for Financial Studies Working Paper, 713.
[https://doi.org/10.2139/ssrn.4515593]
- Buchanan, B.G., 2005. “A (Very) Brief History of Artificial Intelligence”, Ai Magazine, 26(4): 53-60.
-
Butler, L., Yigitcanlar, T., and Paz, A., 2020. “How can Smart Mobility Innovations Alleviate Transportation Disadvantage? Assembling a Conceptual Framework through a Systematic Review”, Applied Sciences, 10(18): 6306.
[https://doi.org/10.3390/app10186306]
- Cao, Y., Li, S., Liu, Y., Yan, Z., Dai, Y., Yu, P.S., and Sun, L., 2023. A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT, arXiv preprint, arXiv: 2303.04226, .
-
Diao, M., Kong, H., and Zhao, J., 2021. “Impacts of Transportation Network Companies on Urban Mobility”, Nature Sustainability, 4: 494–500.
[https://doi.org/10.1038/s41893-020-00678-z]
-
Grindsted, T.S., Christensen, T.H., Freudendal-Pedersen, M., Friis, F., and Hartmann-Petersen, K., 2022. “The Urban Governance of Autonomous Vehicles – In love with AVs or Critical Sustainability Risks to Future Mobility Transitions”, Cities, 120: 103504.
[https://doi.org/10.1016/j.cities.2021.103504]
- Holtzman, A., Buys, J., Forbes, M., and Choi, Y., 2020. The Curious Case of Neural Text Degeneration, arXiv preprint, arXiv: 1904.09751, .
-
Leal Filho, W., Abubakar, I.R., Kotter, R., Grindsted, T. S., Balogun, A.L., Salvia, A.L., and Wolf, F., 2021. “Framing Electric Mobility for Urban Sustainability in a Circular Economy Context: An Overview of the Literature”, Sustainability, 13(14): 7786.
[https://doi.org/10.3390/su13147786]
-
LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. 1998. “Gradient-Based Learning Applied to Document Recognition”, Proceedings of the IEEE, 86(11): 2278-2324.
[https://doi.org/10.1109/5.726791]
-
McCulloch, W.S. and Pitts, W. 1943. “A Logical Calculus of the Ideas Immanent in Nervous Activity”, The Bulletin of Mathematical Biophysics, 5: 115-133.
[https://doi.org/10.1007/BF02478259]
-
Miskolczi, M., Földes, D., Munkácsy, A., and Jászberényi, M., 2021. “Urban Mobility Scenarios Until the 2030s”, Sustainable Cities and Society, 72: 103029.
[https://doi.org/10.1016/j.scs.2021.103029]
-
Oh, C.Y., Song, Y.Y., and Kim, T.H., 2023. “The IPCC and the Sixth Assessment Cycle Report: Centered on the Top 10 Carbon Neutral Technologies”, NIGT Focus, 1-22.
오채운·송예원·김태호, 2023. “IPCC 제6차 평가보고서 종합보고서 기반, 기후기술 대응 시사점: 탄소중립 10대 핵심기술을 중심으로”, 「NIGT Focus」, 1-22. - Penedo, G., Malartic, Q., Hesslow, D., Cojocaru, R., Alobeidli, H., Cappelli, A., and Launay, J., 2023, “The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data Only”, Proceedings of the NIPS ’23: 37th International Conference on Neural Information Processing Systems, New Orleans LA USA.
-
Pérez-Martínez, I., Martínez-Rojas, M., and Soto-Hidalgo, J.M., 2023. “A Methodology for Urban Planning Generation: A Novel Approach Based on Generative Design”, Engineering Applications of Artificial Intelligence, 124: 106609.
[https://doi.org/10.1016/j.engappai.2023.106609]
- Piccinini, E., Flores, C.K., Vieira, D., and Kolbe, L.M., 2016. “The Future of Personal Urban Mobility Towards Digital Transformation”, Wirtschaftsinformatik (MKWI), 55-66.
-
Rosenblatt, F., 1958. “The Perceptron: A Probabilistic Model For Information Storage And Organization In The Brain”, Psychological Review, 65(6): 386-408.
[https://doi.org/10.1037/h0042519]
-
Shin, T., Razeghi, Y., Logan, R.L., Wallace, E., and Singh, S., 2020. “AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts”, Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, 4222–4235.
[https://doi.org/10.18653/v1/2020.emnlp-main.346]
-
Yang, D., Zhang, A.N., and Yan, W., 2017. “Performing Literature Review Using Text Mining, Part I: Retrieving Technology Infrastructure Using Google Scholar and APIs”, Proceedings of 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA.
[https://doi.org/10.1109/BigData.2017.8258313]
-
Yigitcanlar, T., Wilson, M., and Kamruzzaman, M., 2019. “Disruptive Impacts of Automated Driving Systems on the Built Environment and Land use: An Urban Planner’s Perspective”, Journal of Open Innovation: Technology, Market, and Complexity, 5(2): 1-17.
[https://doi.org/10.3390/joitmc5020024]
-
Zhu, J.J., Jiang, J., Yang, M., and Ren, Z.J., 2023. “ChatGPT and Environmental Research”, Environmental Science & Technology, 57(46): 17667-17670.
[https://doi.org/10.1021/acs.est.3c01818]
- Ziegler, D.M., Stiennon, N., Wu, J., Brown, T.B., Radford, A., Amodei, D., and Irving, G., 2019. “Fine-tuning Language Models from Human Preferences”, arXiv preprint, arXiv: 1909.08593, .
-
Zuev, D., Tyfield, D., and Urry, J., 2019. “Where is the Politics? E-bike Mobility in Urban China and Civilizational Government”, Environmental Innovation and Societal Transitions, 30: 19-32.
[https://doi.org/10.1016/j.eist.2018.07.002]
- Learn Prompting, “Prompt Engineering Guide”, Accessed October 9, 2023. https://learnprompting.org/docs/intro/
- Lim, J., 2019.11.13. “Singapore’s AI Strategy to Focus First on Municipal Services, Education, Health among Others”, https://www.todayonline.com/singapore/singapores-ai-strategy-focus-first-municipal-services-education-health-among-others
- Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever, I., 2019. “Language Models are Unsupervised Multitask Learners”, https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf