Final publication date 28 May 2021
지역 간 노동생산성 차이의 결정요인과 정책방향
Abstract
This paper attempts to analyze the determinants of regional differences in labor productivity and suggest a policy direction based on the results. The component decomposition of the productivity difference was modeled using Esteban’s (2000) method, and the panel regression analysis method was employed to determine the key factors for the labor productivity differences. It appears that the key component for the differences is the competitiveness component and that the determinants of this key component differ by region. In Group I (Ulsan, Chungnam, etc.), ΔR&D (R&D differences) comprise the key determinant. In Group II (Seoul, Incheon, Gyeonggi, etc.), ΔHC (human capital differences) comprise the key determinant. Finally, In Group III (Busan, Deagu, etc.), ΔINV (investment differences) comprise the key determinant. These results imply that policies should be comprehensively considered in terms of the regional production environment, industrial characteristics, and labor productivity differences.
Keywords:
Labor Productivity Difference, Shift-Share Model, Cluster Analysis, Panel Analysis키워드:
노동생산성 차이, 변이할당모형, 군집분석, 패널회귀분석Ⅰ. 서 론
1. 연구의 배경 및 목적
OECD(2018)는 2016년 현재 우리나라의 평균 지역 간 노동생산성의 차이가 22개국 중 5위로 높은 수준이라고 발표하였다. 이러한 차이는 지역 간 소득 불균형의 주요한 요인이기 때문에 이를 줄이기 위한 정책적 노력이 필요다고 언급했다. 다시 말해 지역 간 균형발전을 위해서는 노동생산성 차이를 줄이는 정책에 초점을 두어야 한다.
지역 간 노동생산성 차이를 발생시키는 요인을 찾기 위해서는 기본적으로 지역 산업구조의 특성을 고려해야 한다. 왜냐하면 각 지역이 직면한 생산 환경과 이에 따른 산업구조 특성이 다르기 때문이다. 그러나 문헌을 살펴보면, 국내연구는 대부분 산업의 노동생산성 결정요인 등과 같이 결과에 초점을 두었거나, 지역 간 노동생산성 차이에 대한 추이 및 지역 간 노동생산성 수렴 분석 등 현황에 초점을 두었다. 반면 해외연구는 다수의 연구들이 존재하지만, 지역 간 노동생산성의 차이보다는 국가 간 차이에 초점을 두어왔으며, 노동생산성 차이를 일으키는 결정요인에 대한 연구는 드문 실정이다(Esteban, 2000; Ezcurra et al., 2005; 김영수 외, 2009; 박추환, 2012; 정선영, 2013). 정리하면, 기존 연구들은 노동생산성 차이 원인보다는 현황에 초점을 두거나, 생산성 자체를 높일 수 있는 요인을 밝히는 데 집중하였다. 따라서 노동생산성 차이에 대한 연구 부족으로 노동생산성 차이를 줄이기 위한 근본적인 정책 마련에 한계가 있다고 판단된다.
본 연구는 지역 간 노동생산성 차이를 요소(component)별로 분해하고 핵심요소(key component)의 결정요인분석과 그에 따른 정책방향을 제시하는 데 목적이 있다. 본 연구는 총 5개의 절로 구성된다. 2절에서는 관련 연구를 고찰하고 기존 연구의 한계와 본 연구와의 차별성을 제시한다. 3절에서는 지역별 산업 간 노동생산성 차이의 요소분해와 핵심요소 및 핵심요소의 결정요인을 분석하는 모형이 설정된다. 모형은 크게 Esteban(2000)이 사용한 수정된 shift-share분석 부분과 패널회귀분석 부분으로 구성된다. 전자는 노동생산성 차이를 세 가지 요소 즉, 산업구조요소, 경쟁력 요소, 할당요소로 분해하기 위하여 이용되며, 후자는 핵심요소와 그 요소에 대한 결정요인을 분석하기 위해서 사용된다. 4절에서는 3장에서 구축된 모형에 대한 분석결과를 제시한다. 마지막으로 5절에서는 연구의 종합 및 결론을 제시한다.
Ⅱ. 관련연구 고찰
국내ㆍ외의 노동생산성 관련연구는 다양한 주제로 많은 연구가 진행되어 왔다. 이 중 대부분의 연구들은 투자, 임금, 규제, 인구구조, 노동생산성 결정요인 등의 인관관계분석이거나 노동생산성 추이, 수렴 등 현황 분석 등이다. 본 연구에서는 이중에서 주제가 비슷한 노동생산성 결정요인과 차이에 대한 관련 연구를 중심으로 살펴본다.
노동생산성 결정요인 연구는 제조업, 서비스업, 기업규모 등에서 자본집약도, 인적자본, 연구개발투자 등이 노동생산성에 미치는 영향을 분석하는 데 초점을 두었다(황수경, 2008; 김영수 외, 2009; 박추환, 2012; 하봉찬, 2014; 이근희ㆍ표학길, 2015; 최성환ㆍ김홍배, 2017). 이 중 이근희ㆍ표학길(2015)은 기업규모별 노동생산성 격차도 분석하였는데, 자본집약도가 높은 업종일수록 노동생산성이 높고, 노동집약도가 높은 업종에서 낮은 경향이 있다고 밝혔다. 특히 최성환ㆍ김홍배(2017)는 노동생산성 향상 정책은 지역별 특성과 그 수준을 고려하여 수립되어야 한다는 것을 제시하여 기존연구와의 차이를 두었다.
노동생산성 차이에 관한 연구는 Esteban(2000)을 시작으로 EU지역에서 많이 연구되었다. Esteban(2000)은 전통적 shift-share 분석을 응용하여 노동생산성의 차이를 산업혼합 요소(industry-mix component), 생산성 차이 요소(productivity differentials component), 할당요소(allocative component)들로 분해한 후 회귀분석을 이용하여 생산성 차이요소가 핵심요소라고 밝혔다. 이후 Ezcurra et al.(2005), Gallo and Kamrianakis(2011), Kataoka(2011), O’Leary and Webber(2014) 등의 연구자들도 같은 방법을 이용하여 동일한 결과를 얻었다. 국내에서는 최성환 외(2018)가 호남권을 대상으로 같은 방법을 사용하여 요소들의 영향력에 대한 공간분포와 차이를 줄이기 위한 정책방향을 제시하였다.
국내외 관련연구들을 정리하면, 연구의 한계는 크게 두 가지로 정리할 수 있다. 첫째, 노동생산성 차이를 줄이기 위한 주요 요인(factor)을 밝혀내지 못하였다. 다시 말해, 노동생산성 차이의 핵심요소는 제시하였으나, 그 요소를 결정하는 요인에 대한 분석은 제시하지 못하였다. 둘째, 패널데이터(panel data)의 특성을 고려하지 못하였다. 관련연구들은 지리가중회귀 혹은 일반 회귀분석을 이용하여 분석하여 패널데이터에 대한 고려하지 못하였다. 이럴 경우, 개체특성 혹은 관찰되지 않은 누락변수에 대한 처리를 해주지 못하기 때문에 분석된 추정량은 편의가 있는 추정량을 얻을 수 있다(한치록, 2019). 따라서 본 연구에서는 Esteban의 수정된 변이할당모형과 패널회귀모형을 이용하여 노동생산성 차이의 핵심요소와 결정요인을 분석하고, 노동생산성 차이를 줄이기 위한 지역별 정책을 제시하도록 한다.
Ⅲ. 분석모형 설정
본 절은 분석모형이 구축되는데 크게 두 부분으로 구성된다. 첫 번째는 Esteban(2000)이 사용한 수정된 변이-할당(Shift-share)법을 이용하여 우리나라의 지역 간 노동생산성 차이를 세 가지 요소로 구분하는 것이다. 두 번째는 다시 두 단계로 구분된다. 첫 번째는 구분된 요소들 중에서 핵심요소를 결정하는 것이며, 두 번째는 핵심요소에 대한 결정요인을 도출하는 것이다.
1. 노동생산성 차이의 분해
전통적 변이할당분석은 각 산업의 성장을 국가성장, 산업구조, 그리고 경쟁요인의 3가지로 구분하여 지역경제를 분석한다(김홍배, 2016). 그러나 Esteban은 전통적 변이할당법을 수정하여 노동생산성 차이를 산업혼합 요소(industry-mix component), 생산성 차이 요소(productivity differentials component) 그리고 할당요소(allocative component)로 구분하였다. 본 연구에서는 그의 방법을 사용하되, 구성요소에 대한 용어는 산업구조 요소(industry structure component), 경쟁력 요소(competitiveness component), 혼합요소(Composite component)로 용어를 변경한다. 이러한 이유는 첫째, 산업혼합요소는 노동생산성 차이를 지역과 전국의 산업구성 비율차이로 설명하는 부분이므로 산업구조요인으로 변경하는 것이 직관적이다. 둘째, 생산성 차이 요소는 노동생산성 차이를 지역과 전국 평균 노동생산성 차이로 설명하는 부분이다. 여기서 노동생산성 차이를 노동생산성 차이로 설명한다는 것으로 용어가 중복되며, 노동생산성은 지역의 경쟁력과 직결된다는 지역경제학자들의 기존 연구를 따르기로 한다(Porter, 2001). 마지막으로 할당요소는 앞의 두 요소를 혼합한 형태이므로 혼합요소로 용어를 변경한다.
수정된 변이할당법을 구체적으로 유도하면 다음과 같다. 먼저 지역 혹은 국가의 평균 노동생산성은 식 (1)과 같이 산업별 종사자 수 비율과 노동생산성의 가중평균으로 나타낼 수 있다.
| (1) |
- : t년도 지역(전국) 노동생산성
- : t년도 전국 산업 i의 노동생산성()
- : t년도 지역 r산업 i의 노동생산성()
- : t년도 전국 산업 i의 종사자 수 비율()
- : t년도 지역 r산업 i의 종사자 수 비율()
식 (1)에서 t년도 지역의 노동생산성을 종사자 수 비율과 노동생산성과의 역할을 구분하기 위하여 다시 표현하면 아래의 식 (2)와 같이 표현할 수 있다.
| (2) |
식 (2)를 약간의 대수를 사용하여 정리하면, 식 (3)과 같이 t년도의 지역 간 노동생산성 차이는 세 부분으로 구분하여 나타낼 수 있다.
| (3) |
식 (3)을 간단히 표현하면 식 (4)와 같다. 구체적으로 식 (3)의 우측 첫 번째 항은 식 (4)의 우측 첫 번째 항과 같으며, 식 (3)의 두 번째와 세 번째는 식 (4)의 두 번째와 세 번째와 같다.
| (4) |
- : t년도 지역 r의 지역간 노동생산성 차이,
- : t년도 지역 r의 산업구조 요소,
- : t년도 지역 r의 경쟁력 요소,
- : t년도 지역 r의 혼합요소.
각 요소에 대한 구체적인 설명은 다음과 같다. 첫째, 산업구조 요소(μi,t)는 노동생산성의 차이를 지역과 전국의 산업별 구성의 차이에 기인함을 나타낸다. 구체적으로 모든 지역의 산업별 노동생산성이 같다고 가정하면, 노동생산성의 차이는 전국과 지역의 산업구성 차이에 의해서 결정된다는 것이다. 따라서 이 값이 양(+)이라면, 해당지역에 특정산업의 구성 비율이 전국보다 높다는 것을 의미한다. 반대의 경우라면 해당지역의 특정산업의 구성이 전국보다 낮음을 의미한다.
둘째, 경쟁력 요소()는 노동생산성의 차이를 지역과 전국의 산업별 경쟁력 차이를 측정한다. 구체적으로 전국과 지역의 산업구성이 동일하다 가정하면, 노동생산성의 차이는 경쟁력의 차이에 기인함을 의미한다. 따라서 이 값이 양(+)이면 그 지역의 노동생산성은 전국 평균보다 높다는 것을 의미한다. 반대의 경우라면 그 지역의 노동생산성이 전국 평균보다 낮다는 것을 의미한다.
마지막으로 혼합요소()는 산업구조와 경쟁력의 상호작용을 포착하여 생산성이 전국 평균보다 높은 분야에서 지역의 전문화 정도를 나타낸다. 이 값이 양수이면 해당 지역은 전국 평균보다 노동생산성이 높은 산업들로 구성되어 있다. 반대의 경우라면 노동생산성이 낮은 산업들로 구성되어 있음을 의미한다. 따라서 이 값은 다양한 산업분야에서 자원을 할당하는 지역의 효율성 지표로 간주할 수 있다(Esteban, 2000).
2. 핵심요소와 결정요인 도출
핵심요소(key component)는 패널회귀모형을 이용하여 도출되며, 구체적인 모형은 아래의 식 (5)~(7)과 같이 각 요소별 단순패널회귀모형으로 구축된다. 왜냐하면 각 요소는 노동생산성 차이 값을 분해하여 나타낸 것이기 때문이다. 그리고 핵심요소는 설명력(R2)이 높은 모형의 것으로 한다. 왜냐하면 노동생산성 차이의 변동을 어떤 요소가 가장 잘 설명하는지가 중요하기 때문이다.
| (5) |
| (6) |
| (7) |
- ζ(ㆍ) : 절편항,
- : (ㆍ)요인의 관찰되지 않은 객체특성 효과,
- λ(ㆍ),t : (ㆍ)요인의 관찰되지 않은 시간특성 효과,
- ν(ㆍ),t : 오차의 확률적 교란항, : 확률적 교란항.
핵심요소에 대한 결정요인은 아래의 식 (8)과 같이 분석된다. 모형이 일반적인 형태로 표현된 이유는 핵심요소에 따라 독립변수가 다르게 결정될 수 있기 때문이다. 또한 주요 결정요인은 각 요인의 계수값(coefficient value)의 부호와 크기를 비교하여 정한다. 왜냐하면 결정요인은 핵심요소에 미치는 영향력이 큰 변수가 더 중요하기 때문이다.
| (8) |
- : t년도 지역 r의 핵심요소,
- : t년도 지역 r의 결정요인 변수,
- β0 : 절편항, βi : 설명변수의 계수,
- : t년도 지역 r의 확률적 교란항,
- : (ㆍ)요인의 관찰되지 않은 객체특성 효과,
- : (ㆍ)요인의 관찰되지 않은 시간특성 효과.
패널회귀분석은 오차항(ϵit)을 고정된 상수로 볼 것인지 아니면 확률변수로 볼 것인지에 따라 각각 고정효과모형(Fixed Effect model)과 확률효과모형(Random Effect model)으로 구분된다. 본 연구에서는 이 중 어떤 모형을 선택할 것인지에 대해서는 B-P 검정, Chow 검정, Hausman 검정 등을 바탕으로 선정한다(이희연ㆍ노승철, 2012).
3. 지역의 그룹화 및 분석자료
분석은 각 지역을 노동생산성 차이가 유사한 그룹으로 구분하여 실시한다. 왜냐하면 지역의 산업특성 및 생산환경과 노동생산성 차이의 수준이 종합적으로 고려되어야 하기 때문이다. 또한 지역별 특성에 따라 정책변수가 미치는 영향이 다를 수 있기 때문이다.
지역별 그룹화는 군집분석을 사용한다. 왜냐하면 이 분석은 군집의 수 결정에 어려움이 존재하지만, 많은 데이터를 처리하고 쉽게 계산할 수 있다는 장점이 있기 때문이다. 또한 최근 머신러닝 기법을 이용하여 최적의 군집 수를 결정할 수 있기 때문이다.
마지막으로 노동생산성 차이의 핵심요소를 도출하기 위한 자료는 통계청의 지역별 경제활동별 부가가치와 종사자 수 자료를 이용한다. 분석기간은 산업분류의 일관성을 유지하기 위하여 2010년부터 2018년까지(산업분류 10차 개정)로 정하였다.
Ⅳ. 모형 적용
1. 노동생산성 차이의 요소별 수준
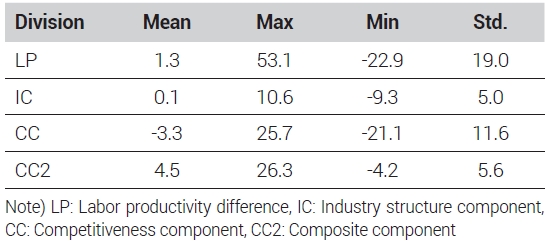
식 (3)에서 의해서 계산된 노동생산성 차이와 각 요소들의 기초통계량은 <표 1>에 제시하였다. 전체 패널자료에서 종속변수인 노동생산성 차이(LP)의 평균은 1.3 백만 원으로 나타났다. 각 독립변수인 산업구조 요소(IC)의 평균은 0.1백만 원, 경쟁력요소(CC)의 평균은 -3.3백만 원, 마지막으로 혼합요소(AC)의 평균은 4.5백만 원으로 나타났다.

Basic statistics by component of labor productivity difference (Unit: million won)
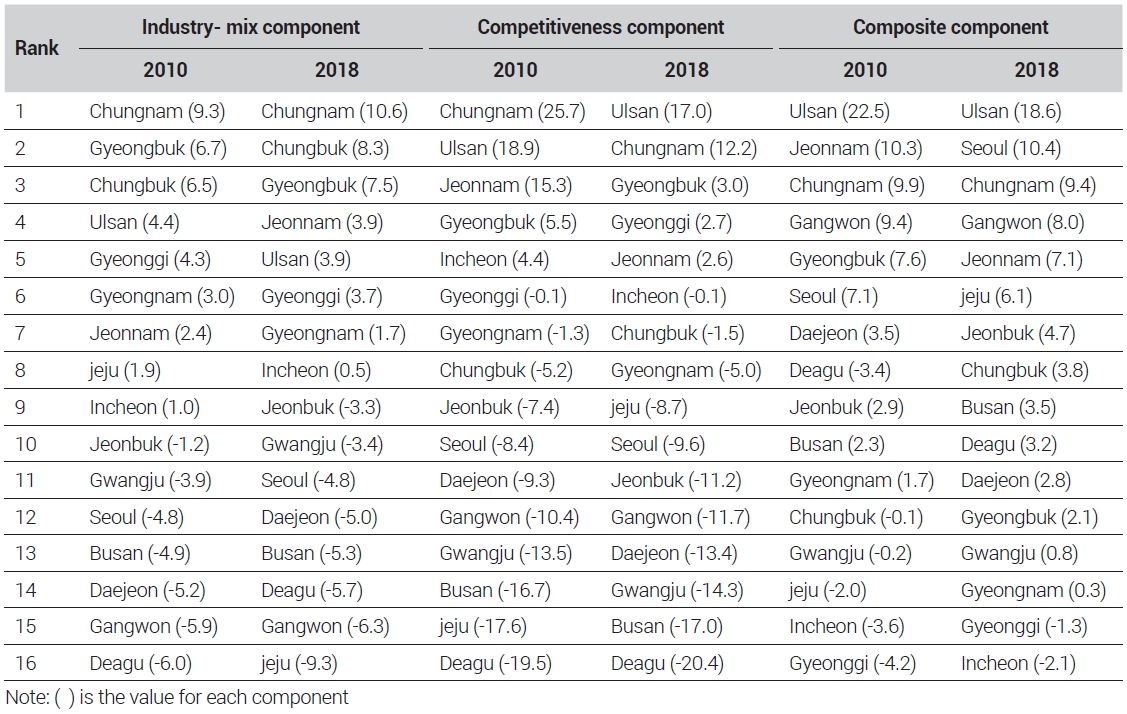
<표 2>와 <표 3>은 각각 노동생산성의 차이와 각 요소별 수준을 제시한 것이다. 구체적으로 지역별 노동생산성 차이()의 경우, 노동생산성이 전국 평균보다 가장 높은 지역은 울산이며, 그 다음으로는 충남, 전남, 경북 순으로 나타났다. 반대로 가장 낮은 지역은 부산과 대구로 분석되었다.
Regional difference in labor productivity(Unit: million won)
Results of labor productivity difference among regions and nation by components (Uint: milion won)
또한 노동생산성 차이 순위가 상승된 지역은 충북(7위→5위), 경기(8위→6위), 서울(10위→9위) 등으로 나타났다. 반대로 하락한 지역은 경남(5위→8위), 인천(6위→7위), 전북(9위→10위) 등이다.
각 요소별 측정된 자료의 수준을 2018년 기준으로 설명하면, 산업구조요소()의 경우, 가장 높은 값을 보인 지역은 충남이며 그 다음으로는 충북, 경남, 전남 순으로 높았다. 반대로 가장 낮은 지역은 제주이며, 그 다음으로는 강원, 대구 등의 순이다. 또한 분석기간 동안 순위가 상승된 지역은 충북(3위→2위), 인천(9위→8위), 전북(10위→9위) 등으로 분석되었다.
경쟁력 요소()의 경우는 울산이 가장 높으며, 그 다음으로는, 충남, 경북, 경기 순으로 나타났다. 반대로 가장 낮은 지역은 대구이며, 그 다음으로는 부산, 광주 순으로 나타났다. 순위가 상승한 지역은 울산(2위→1위), 경북(4위→3위), 경기(6위→4위) 등이다.
마지막으로 혼합요소()의 경우는 가장 높은 지역이 울산이며, 그 다음으로는 서울, 충남, 강원 순으로 나타났다. 반대로 가장 낮은 지역은 대구이며, 그 다음으로는 경기, 경남, 광주 순으로 나타났다. 분석기간 동안 순위가 상승한 지역은 서울(8위→6위), 제주(14위→6위), 전북(9위→8위), 충북(12위→7위) 등의 순으로 나타났다.
2. 핵심요소와 결정요인
군집분석은 비계층 군집분석 중 가장 많이 사용되는 k-means 방법을 이용하며, 최적 군집의 수는 R의 Nbclust 패키지를 이용하여 추정한다. 분석결과, 군집의 수는 3개가 최적으로 계산되었으며, 각 군집에 속한 지역과 추이는 각각 <표 4>와 <그림 1>과 같다.
Regions by clustering groups

Trend of labor productivity differences by clustering groups
각 군집에 대해 간략히 설명하면 다음과 같다. 먼저 그룹Ⅰ은 울산, 충남, 전남, 경북지역으로 평균 노동생산성 차이가 29.7 백만 원으로 가장 높았다. 그룹Ⅱ는 서울, 인천, 경기, 충북, 경남지역으로 평균 노동생산성 차이는 0.5백만 원으로 두 번째로 높은 지역이다. 마지막으로 그룹Ⅲ은 부산, 대구, 광주, 대전, 강원, 전북, 제주지역으로 평균 노동생산성 차이가 전국보다 낮다. 이러한 결과는 그룹Ⅰ에 속한 지역의 노동생산성은 전국 평균 노동생산성보다는 것을 알 수 있다. 그리고 그룹Ⅱ 노동생산성이 전국 평균과 유사한 수준이며 마지막으로 그룹Ⅲ은 노동생산성이 전국 평균을 밑도는 것을 의미한다.
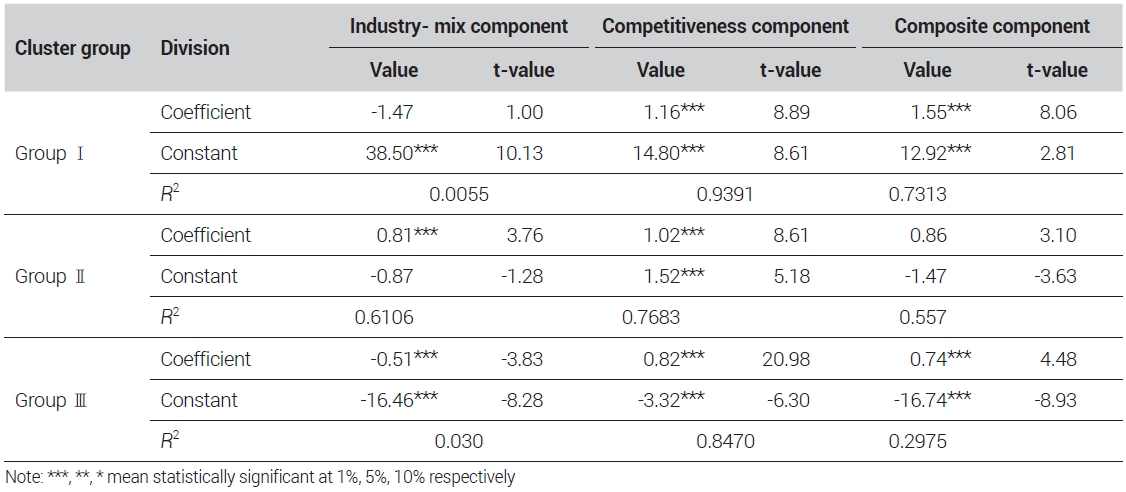
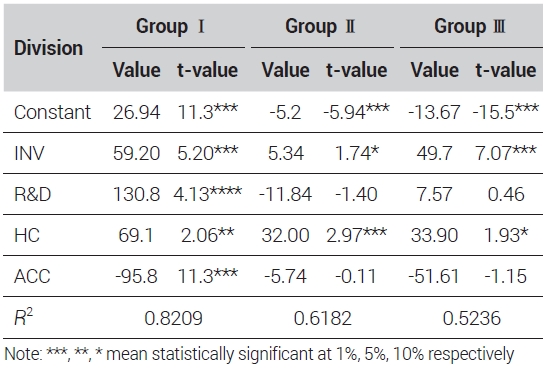
<표 4>의 결과를 바탕으로 그룹별 노동생산성 차이의 핵심요소를 도출하기 위하여 식 (5)~(7)를 분석하였다. 분석은 Hausman 검정 결과를 바탕으로 고정효과 모형을 이용하였으며, 이에 대한 결과는 <표 5>에 제시된 바와 같다. 결과를 정리하면, 모든 그룹에서 3개의 요소 중 경쟁력 차이 요소가 핵심요소로 분석되었다. 다시 말해, 각 지역 간 노동생산성 차이는 지역 간 경쟁력 차이에 기인함을 의미한다. 이러한 결과는 Esteban(2000), Ezcurra et. al.(2005) 등의 연구결과와도 같다. 즉 우리나라도 지역 간 노동생산성 차이는 지역 간 경쟁력 차이에 의해서 발생된다는 것을 알 수 있다.
Results of panel regression on components in clustering groups
지역 간 경쟁력 차이의 결정요인 분석은 식 (8)을 이용한다. 구체적으로, 종속변수는 경쟁력 요소()가 되고, 독립변수는 지역 경쟁력에 영향을 주는 결정요인들로 구성된다. 본 연구에서는 지역경쟁력 결정요인을 선행연구들에 의해 검증된 주요한 변수들로 구성한다(Poter, 2001; Bowes, 2003; Gardiner et al., 2004; OECD, 2005; Aula and Harmaakorpil, 2008; Wahyuni et al., 2009; 김정홍 외, 2010).
선행연구들에서는 지역 경쟁력 요인을 인프라, 노동력, 정책ㆍ제도, 지리적 요소 등으로 구분하였다. 이 중에서 노동력, 접근성, 기업 내재적 요인 등이 지역경쟁력과 상관관계가 높은 주요한 요인이라고 밝혔다. 따라서 본 연구에서의 결정요인은 이들 변수를 준용한다. 그리고 지역투자변수를 새롭게 추가하며, 지역의 정책ㆍ제도를 대표하는 변수로 활용한다. 왜냐하면 지역투자가 많은 지역은 지역의 투자환경에 대한 정책ㆍ제도적 지원이 우수하다고 판단할 수 있기 때문이다.
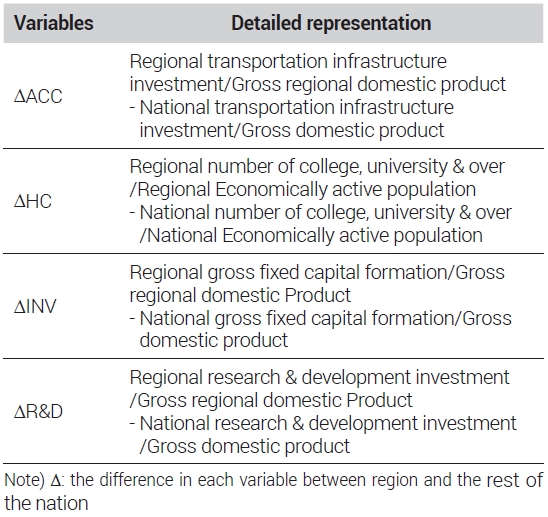
분석을 위한 독립변수는 지역과 전국 평균과의 차이로 표현된다. 왜냐하면 지역 간 경쟁력 차이는 지역 간 독립변수들의 차이에 의해 발생되기 때문이다, 이에 대한 자세한 설명은 다음과 같다. 지역접근성(ΔACC)은 지역 내 총생산 대비 교통시설 건설기성액 비율로 표현하며, 측정은 각 지역과 전국과의 차이로 나타낸다. 인적자본(ΔHC)은 지역별 경제활동인구 대비 대학졸업이상 경제활동인구 비율로 표현되며, 마찬가지로 측정은 전국과의 차이로 나타낸다, 지역투자(ΔINV)와 혁신역량(ΔR&D)은 각각 총고정자본형성이 지역별 총생산에서 차지하는 비율과 지역별 총생산에서 연구개발 투자가 차지하는 비율로 표현된다. 또한 그 차이는 다른 두 변수와 마찬가지로 전국과의 차이로 측정한다. 변수에 대한 정의와 측정방법은 <표 6>에 제시된 바와 같다.
Specification of independent variables
결정요인 분석결과는 <표 7>에 제시된 바와 같다. 구체적으로 그룹Ⅰ에서는 지역투자의 차이(ΔINV), 연구개발의 차이(ΔR&D), 인적자본의 차이(ΔHC), 접근성의 차이(ΔACC)의 모든 변수가 유의하게 나타났다. 그룹Ⅱ와 그룹Ⅲ은 모두 지역투자(ΔINV)와 인적자본의 차이(ΔHC)가 유의미하게 나타났다. 다만 두 그룹에서 통계적 유의수준이 높은 변수는 그룹Ⅱ는 인적자본의 차이(ΔHC)이며, 그룹Ⅲ은 지역투자 차이(ΔINV)로 서로 다르게 나타났다. 이러한 분석결과는 김정홍 외(2010)의 결과처럼 지역경쟁력은 지역별로 중요요인이 다르게 나타났다는 것은 유사하다. 하지만 지역별 주요한 결정요인과 지역의 구분에 대해서는 본 연구와는 차별성을 갖는다.
Results of determinant analysis by clustering groups
이러한 분석결과는 지역별 노동생산성 차이를 줄이기 위해서는 지역별 차별화된 정책을 수행해야 한다는 시사점을 제공한다. 구체적으로 울산, 충남, 전남 등의 지역(그룹Ⅰ)은 노동생산성이 높은 그룹으로 노동생산성의 차이를 전국 평균수준으로 감소시킬 수 있는 접근성(ΔACC)보다는 연구개발(ΔR&D)투자를 확대해야 할 것이다. 이와 더불어 지역투자(ΔINV)와 인적자본(ΔHC)에 대한 수준도 확대시켜야 할 필요가 있다. 다시 말해, 이들 지역은 높은 노동생산성을 유지하고 있으므로 현재와 같이 전국 평균보다 높은 생산성을 유지하거나 높일 수 있도록 중요변수에 대한 확대정책을 추진해야 한다.
다음으로 서울, 인천, 경기(그룹Ⅱ) 등의 지역은 가장 우선적으로 인적자본에 대한 투자를 확대해야 한다. 그 다음으로는 지역투자를 늘릴 수 있도록 유도해야 한다. 마지막으로 부산, 대구, 광주, 대전(그룹Ⅲ) 등의 지역은 최우선 정책으로 지역투자를 증가시켜야 한다. 그 다음으로는 인적자본에 대한 투자를 확대해야 한다.1)
Ⅴ. 요약 및 결론
본 연구의 목적은 지역별 노동생산성 차이의 결정요인과 정책방향을 제시하는 데 그 목적이 있다. 본 연구에서는 Esteban(2000)의 수정된 변이할당 모형과 패널회귀모형을 이용하여 노동생산성 차이의 핵심요소와 그 요소의 결정요인을 도출하였다.
분석결과를 요약하면, 우리나라의 노동생산성 차이는 모든 지역에서 경쟁력 차이에 의해 발생되는 것을 알 수 있었다. 그러나 이 요소를 결정하는 요인은 지역별로 다르게 나타났다. 구체적으로 그룹Ⅰ은 혁신역량이 핵심요인으로 분석되었으며, 그룹Ⅱ는 인적자본 그리고 그룹Ⅲ은 지역투자로 나타났다.
이러한 결과를 바탕으로 지역별 노동생산성 차이를 줄이는 정책을 제시하였다. 구체적으로 그룹Ⅰ은 전국 평균보다 높은 생산성 차이를 나타내므로 현재의 수준을 유지할 수 있도록 연구개발에 대한 투자를 적극적으로 추진하되, 투자와 인적자본에 대한 투자도 병행하는 정책이 필요함을 제시하였다. 그리고 그룹Ⅱ는 인적자본 확대에 대한 정책을 우선적으로 추진해야 함을 제시하였다. 마지막으로 그룹Ⅲ은 그룹Ⅱ와는 반대로 투자 확대를 위한 정책을 우선적으로 추진해야 함을 제시하였다.
이러한 결과를 제시함에 있어서 본 연구는 다음과 같은 한계를 갖는다. 첫째, 노동생산성 차이요소를 세분화하지 못한 것이다. 즉, 노동생산성 차이는 지역 내 요소뿐만 아니라 지역 간의 영향도 고려되어야 한다. 그러나 본 연구에서는 이를 고려하지 못하였다. 만약 이를 고려한다면, 보다 다양한 결과가 도출될 것으로 기대한다.
둘째, 지자체 단위에서의 차이분석과 다양한 결정요인 변수에 대한 고려의 부족이다. 본 연구는 광역단위의 자치단체를 공간적 범위로 고려하였다. 그러나 지역 간 노동생산성 차이는 시ㆍ군ㆍ구 수준에서 더 분명할 것으로 판단된다. 따라서 지역의 구분을 보다 세밀히 하여 지역 간 노동생산성 차이를 분석하는 것이 필요하겠다. 이와 더불어 결정요인 분석을 위한 변수는 정치환경, 어메니티 등 정성적인 요소도 차이를 설명할 수 있으므로 이에 대한 추가적인 고려가 필요하다.
Notes
References
-
김영수ㆍ변창욱ㆍ이상호, 2009. 「지역산업의 생산성과 정책효과 분석 방법 연구」, 서울: 산업연구원.
Kim, Y.S., Byun, C.W., and Lee, S.H., 2009. A Study on the Method of Analyzing the Productivity and Policy Effects of Regional Industries, Seoul: Korea Institute. -
김정홍ㆍ변창욱ㆍ김동수, 2010. 「지역경쟁력의 원천 및 특성에 관한 연구」, 서울: 산업연구원.
Kim, J.H., Byun, C.W., and Kim, D.S., 2010. A Study on the Source and Characteristics of Regional Competitiveness, Seoul: Korea Institute for Industrial Economics & Trade. -
김홍배, 2016. 「도시 및 지역경제 분석론」, 서울: 기문당.
Kim, H.B., 2016. Urban and Regional Economic Analysis, Seoul: Gimundang. -
박추환, 2012. “절대적 수렴가설을 통한 지역별 서비스업 노동생산성 수렴연구: 16개 광역시ㆍ도를 중심으로”, 「지역연구」, 28(4): 79-98.
Park, C.H., 2012. “Regional Income Convergence of the Labor Productivity in Service Industries: The Korean Case”, Journal of the Korea Regional Science Association, 28(4): 79-98. -
이근희ㆍ표학길, 2015. “기업동학, 자원재배분 및 노동생산성 결정요인: 「기업활동조사(2006~2012)」에 기초한 패널분석”, 「한국경제의 분석」, 21(3): 43-114.
Rhee, K.H. and Pyo, H.K., 2015. “Firm Dynamics, Resource Reallocation and Determinants of Labor Productivity: A Panel Analysis from the Korean Firm Level Data (2006~2012), Analysis of Korea Economic, 21(3): 43-114. -
이희연ㆍ노승철, 2012. 「고급통계분석론」, 서울: 법문사.
Lee, H.Y. and Noh, S.C., 2012. Advanced Statistical Analysis, Seoul: Bobmunsa. -
정선영, 2013. “우리나라 생산자서비스산업의 생산성 결정요인: 사업서비스업을 중심으로”, 「산업경제연구」, 26(4): 1659-1690.
Jung, S.Y., 2013. “A Study on the Determinants of Productivity in Korea Business Services”, Journal of Industrial Economics and Business, 26(4): 1659-1690. -
최성환ㆍ김재구ㆍ최명섭, 2018. “호남권역 노동생산성 차이의 국지적 공간분포 및 원인분석”, 「한국지역경제연구」, 16(3): 51-68.
Choi, S.H., Kim, J.G., and Choi, M.S., 2018. “Local Spatial Distribution and Causal Analysis of Labor Productivity Gap in Honam Region”, Korea Regional Economic, 16(3): 51-68. [ https://doi.org/10.34282/krea.2018.16.3.3 ]
-
최성환ㆍ김홍배, 2017. “생산자서비스산업의 노동생산성 결정요인분석과 지역정책방향”, 「국토계획」, 52(4): 171-186.
Choi, S.H. and Kim, H.B., 2017. “Analyzing Key Factors of Labour Productivity in the Regional Producer Service Industries and Directing Policy”, Journal of the Korean Planning Association, 52(4): 171-186. [ https://doi.org/10.17208/jkpa.2017.08.52.4.171 ]
-
하봉찬, 2014. “서비스업 생산성 결정요인 분석”, 「산업경제연구」, 27(3): 1191-1213.
Ha, B.C., 2014. “A Study on the Determinants of Labor Productivity in the Korean Service Industry”, Journal of Industrial Economics and Business, 27(3): 1191-1213. -
한치록, 2017. 「패널데이터강의」, 서울: 박영사.
Han, C.R., 2017. Lecture on Panel Data Analysis, Seoul: Pakyoungsa. -
황수경, 2008. “서비스산업 고용 및 노동생산성 변동의 구조 분석”, 「노동정책연구」, 8(1): 27-62.
Hwang, S.K., 2008. “Structural Analysis of Employment and Labor Productivity in the Service Industry”, Quarterly Journal of Labor Policy, 8(1): 27-62. -
Aula, P. and Harmaakorpil, V., 2008. “An Innovative Milieu– A View on Regional Reputation Building: Case Study of the Lahti Urban Region”, Regional Studies, 42(4): 523-538.
[https://doi.org/10.1080/00343400701543207]
-
Bowes, N., 2003. “The Competitiveness of Former Coalfields: Manufacturing Managers’ Perceptions of Competitiveness Strengths and Weaknesses in South Yorkshire”, Local Economy, 18(2): 135-158.
[https://doi.org/10.1080/0269094032000087866]
- Gardiner, B., Martin, R., and Tyler, P., 2004. “Competitiveness, Productivity and Economic Growth across the European Regions”, Regional Studies, 38(9): 1045-1067.
-
Gallo, J.L. and Kamarianakis, Y., 2011. “The Evolution of Regional Productivity Disparities in the European Union from 1975 to 2002: A Combination of Shift-Share and Spatial Econometrics”, Regional Studies, 45(1): 123-139.
[https://doi.org/10.1080/00343400903234662]
-
Esteban, J., 2000. “Regional Convergence in European and the Industry Mix: a Shift-Share Analysis”, Regional Science and Urban Economics, 30(3): 353-364.
[https://doi.org/10.1016/S0166-0462(00)00035-1]
-
O’Leary, E. and Webber, D.J., 2014. “The Role of Structural Change in European Regional Productivity Growth”, Regional Studies, 49(9): 1548-1560.
[https://doi.org/10.1080/00343404.2013.839868]
-
Kataoka, M., 2011. “Interregional Productivity Differentials: a Shift-Share Decomposition Analysis and Its Application to Post-War Japan”, Letters in Spatial and Resource Sciences, 4(1): 1-7.
[https://doi.org/10.1007/s12076-010-0045-5]
- OECD, 2005. “OECD Regions and Cities at a Glance 2005”, Paris.
- OECD, 2018. “OECD Regions and Cities at a Glance 2018”, Paris.
- Porter, M.E., 2001. “Clusters of Innovation: Regional Foundations of U.S. Competitiveness”, Council on Competitiveness, Washington, DC, Harvard University.
-
Ezcurra, R., Gil, C., Pascual, P., and Rapún, M., 2005. “Regional Inequality in the European Union: Does Industry Mix Matter?”, Regional Studies, 39(6): 679-697.
[https://doi.org/10.1080/00343400500213473]
-
Wahyuni, S., Djamil, I.K., Astuti, S.A. E.S., and Mudita, T., 2010. “The Study of Regional Competitiveness in Batam, Bintan and Karimun”, International Journal of Sustainable Strategic Management, 2(3): 299-316.
[https://doi.org/10.1504/IJSSM.2010.038303]